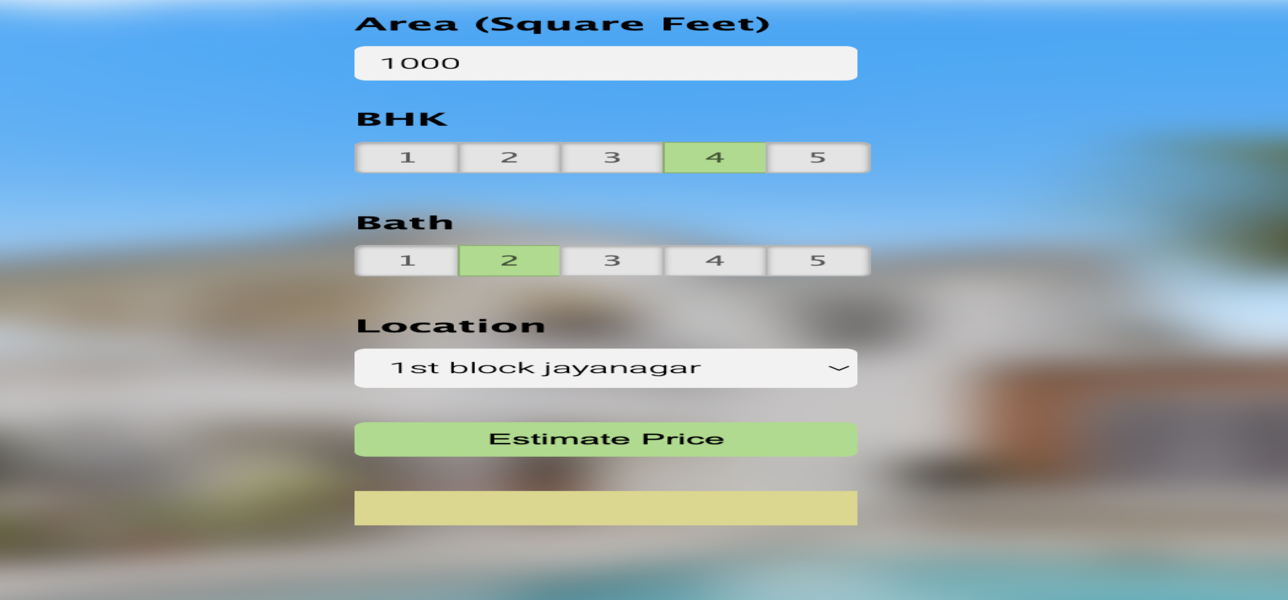
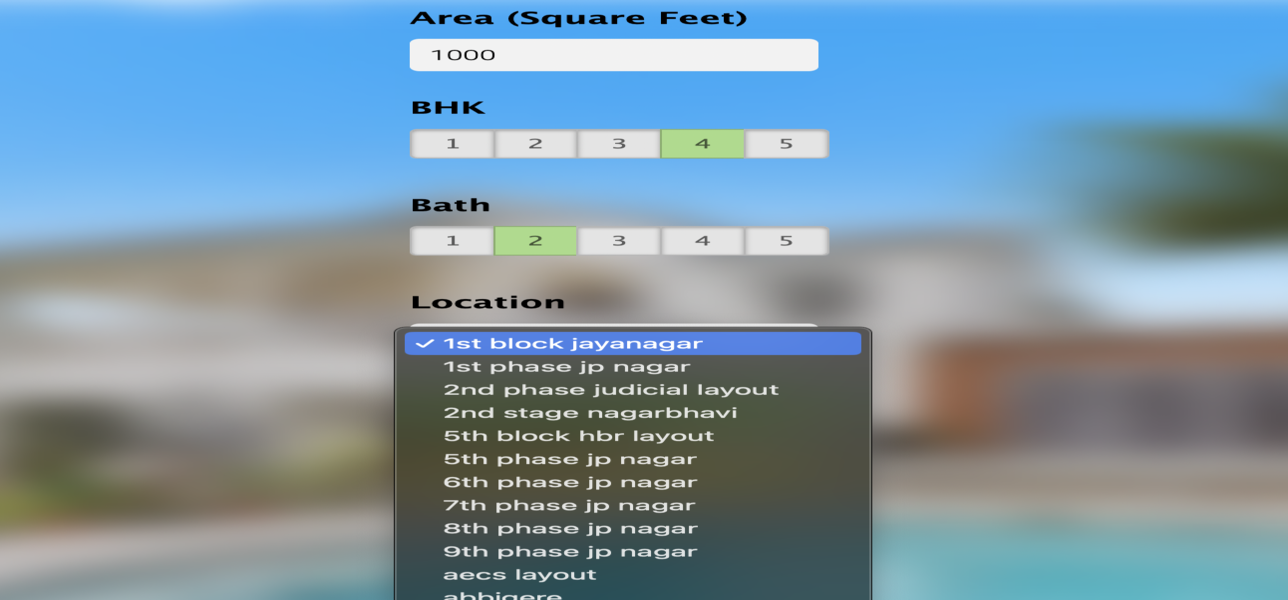
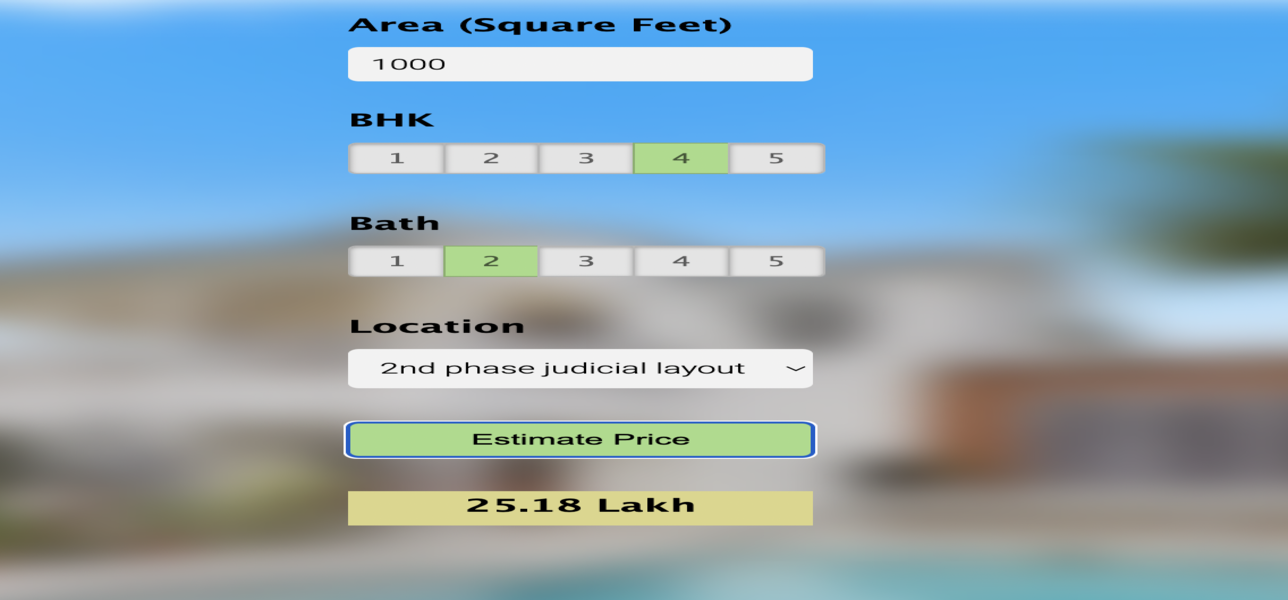
Portfolio Details
- Home
- Portfolio Details
Details
- The project begins with exploratory data analysis to understand the distribution and relationships
between different variables. Data preprocessing techniques are applied to handle missing values,
outliers, and categorical variables. Feature engineering is performed to extract meaningful insights
and enhance the predictive power of the model.
- Several machine learning algorithms, including linear regression, random forests regressor, k-means
clustering and DBSCAN clustering are employed to build and evaluate the predictive model.
- Hyperparameter tuning and cross-validation techniques are used to optimize model performance
and ensure generalizability.
- The model's performance is assessed using evaluation metrics such as K- fold cross validation,R-
squared score, mean square error,R squared value, confusion matrix,accuracy, Silhouette
Coefficient and Davies-Bouldin Index.